GitHub Code Link - https://github.com/0M1J/kubeflow-GNN
Graph Neural Networks (GNNs) are at the forefront of machine learning, excelling at tasks involving complex relational data. However, training these models, especially on massive datasets, presents significant challenges related to scalability, resource management, and distributed computing. This blog post delves into a project that successfully tackled these hurdles by building a robust and scalable infrastructure for GNN model training using Kubeflow and PyTorch Distributed Data Parallel (DDP) on Google Kubernetes Engine (GKE).
Project Overview: Predicting Missing Citations with GNNs (Distributed Training on Kubeflow)
Our core objective was to predict missing citations within a large-scale academic citation network. This is a crucial task in scientific research, enabling better discovery and understanding of knowledge graphs.
The problem can be framed as a link prediction task on a graph. Given an existing citation network, the goal is to identify new or missing citation links between papers. The solution leverages the power of GNNs to learn rich representations of papers (nodes) and then predicts the likelihood of a citation (edge) between them.
This project utilized the ogbl-citation2 dataset from the OGB (Open Graph Benchmark) library. This dataset represents a directed graph of citation networks extracted from the Microsoft Academic Graph (MAG). Each node signifies a paper, equipped with 128-dimensional word2vec features summarizing its title and abstract. Directed edges indicate citations. Crucially, the dataset also includes meta-information like the publication year for each paper.
The prediction task involved dropping two references from each source paper, with these dropped edges serving as validation and test sets. The remaining edges were used for training the model.
System Architecture: A Mesh of Distributed Components
The strength of our solution lies in its well-orchestrated system architecture, designed for distributed machine learning at scale. The entire ecosystem is built upon Kubernetes (GKE), providing the foundational orchestration layer. On top of Kubernetes, Kubeflow acts as the ML platform, streamlining the deployment and management of our training workloads.
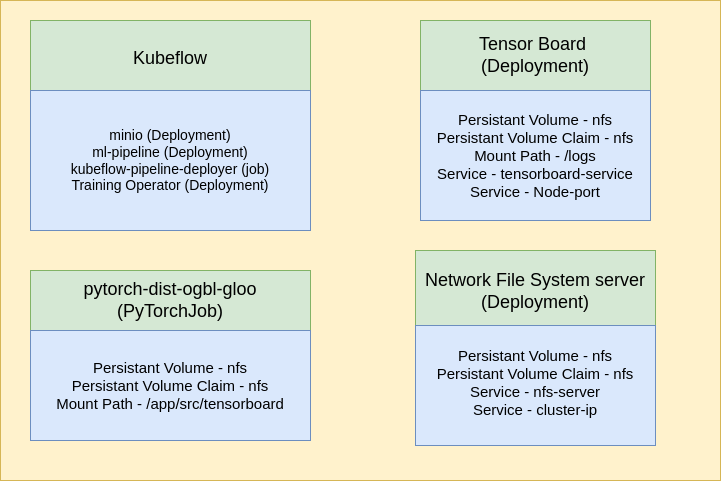
Here’s a breakdown of the key components and their interactions:
- Google Kubernetes Engine (GKE): The bedrock of our infrastructure, providing a managed Kubernetes environment for container orchestration, scaling, and resource management.
- Kubeflow: An open-source ML platform deployed on Kubernetes. It simplifies the deployment of ML workflows, including training and inference, and enables scaling across multiple GPUs and machines. Key Kubeflow components utilized include:
- Kubeflow ML Pipeline: Orchestrates the end-to-end ML workflow, from data preparation to model deployment.
- Kubeflow Training Operator (PyTorchJob): A custom Kubernetes controller specifically designed to run distributed PyTorch training jobs, managing the lifecycle of master and worker pods.
- MinIO: Used as an S3-compatible object storage service within Kubeflow for storing artifacts and data.
- GNN Model (GraphSage with Link Prediction): The core intelligence of our system, implemented using PyTorch Geometric (PyG).
- PyTorch Distributed Data Parallel (DDP): Enables efficient distributed training by replicating the model across multiple GPUs/nodes and synchronizing gradients.
- TensorBoard: For real-time visualization and monitoring of training metrics, logs, and model performance.
- NFS (Network File System): Provides shared, persistent storage for datasets, model checkpoints, and TensorBoard logs, accessible by all worker pods.
The workflow begins with Docker images for the GNN training application pushed to Google Container Registry via Google Cloud Build. Kubeflow’s PyTorchJob operator then leverages these images to deploy and manage distributed training jobs on GKE. Data is accessed from the shared NFS volume, and training progress is logged to the same shared storage, accessible by a dedicated TensorBoard deployment for live monitoring.
The GNN Model and PyTorch Distributed Data Parallel (DDP)
At the heart of our citation prediction system lies a sophisticated GNN model coupled with PyTorch’s powerful distributed training capabilities.
Graph Neural Network (GNN) Model
Our model utilizes a GraphSage GNN for generating robust node embeddings. GraphSage is an inductive framework, meaning it can learn embeddings for nodes not seen during training, making it highly suitable for dynamic graph data. It operates by sampling and aggregating information from a node’s local neighborhood. In our implementation, the SAGEConv layer from PyTorch Geometric (PyG) is used, with aggr="add" for aggregating neighbor features. This approach effectively captures structural and feature information from the graph.
For the link prediction task, we employ a simple yet effective DotProductLinkPredictor. This predictor takes the learned embeddings of two nodes (papers), computes their dot product, and then applies a sigmoid activation function to output a probability score indicating the likelihood of a citation existing between them.
The overall architecture involves:
- Node Embedding: GraphSage layers process the graph to generate a low-dimensional embedding for each paper.
- Link Score Calculation: For a pair of papers, their embeddings are fed into the
DotProductLinkPredictor. - Loss Function: A binary cross-entropy loss with logits is typically used to compare the predicted scores with the true labels (existence or absence of a citation).
PyTorch Distributed Data Parallel (DDP)
To scale GNN training across multiple GPUs and nodes, we integrated PyTorch Distributed Data Parallel (DDP). DDP is a highly efficient approach for data parallelism, where each process (typically running on a separate GPU) holds a replica of the model and processes a distinct mini-batch of data.
Key aspects of DDP implementation in our project include:
- Model Replication: At the start of training, the GNN model is replicated on each worker process.
DistributedSampler: Crucially, theDistributedSamplerensures that each worker receives a unique subset of the overall dataset for each epoch. This prevents redundant computations and ensures all data is processed.- Gradient Synchronization: During the backward pass, after local gradients are computed on each replica, DDP automatically handles the synchronization of these gradients across all processes. This is primarily achieved using an
all-reduceoperation, where the sum of gradients from all replicas is computed and then distributed back to each replica, ensuring all models have identical, averaged gradients. - Buffer Synchronization: DDP also manages the synchronization of model buffers (e.g., batch normalization statistics) across processes, ensuring consistency.
- Gloo Backend: The
GLOObackend was chosen for inter-process communication, known for its reliability and performance in CPU-based distributed training, which is particularly relevant when dealing with large graph structures that might not fully reside on GPU memory.
By combining GraphSage for robust embeddings and PyTorch DDP for scalable training, we achieved a powerful and efficient solution for large-scale GNN-based link prediction.
Kubeflow Integration: Orchestrating Distributed Training Jobs
Kubeflow serves as the control plane for our distributed GNN training, simplifying the complex process of deploying and managing these workloads on Kubernetes. The cornerstone of this integration is the PyTorchJob operator.
The PyTorchJob operator is a custom resource definition (CRD) provided by Kubeflow that understands how to deploy and manage distributed PyTorch training jobs. Instead of manually creating Kubernetes Deployments, Services, and StatefulSets for each master and worker, we define a single PyTorchJob manifest.
Here’s how we configure the PyTorchJob for our GNN training:
YAML
apiVersion: kubeflow.org/v1
kind: PyTorchJob
metadata:
name: pytorch-dist-ogbl-gloo
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: gcr.io/dsd-demo-370521/pytorch-dist-ogbl-gloo:1.0
args:
- --epochs=5
volumeMounts:
- mountPath: /data
name: data-volume
- mountPath: /tensorboard
name: log-data
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: nfs
- name: log-data
persistentVolumeClaim:
claimName: nfs
Worker:
replicas: 3 # Scaled from 1 to 31 workers for experiments
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: gcr.io/dsd-demo-370521/pytorch-dist-ogbl-gloo:1.0
args:
- --epochs=5
volumeMounts:
- mountPath: /data
name: data-volume
- mountPath: /tensorboard
name: log-data
volumes:
- name: data-volume
persistentVolumeClaim:
claimName: nfs
- name: log-data
persistentVolumeClaim:
claimName: nfs
Key Configuration Aspects:
pytorchReplicaSpecs: This section defines the different types of replicas (roles) within the distributed training job.Master: We specify a single master replica (replicas: 1). The master pod is responsible for orchestrating the training process, often the rank 0 process in PyTorch DDP.Worker: We define the number of worker replicas (e.g.,replicas: 3). Each worker pod runs a replica of the model and processes a portion of the data. During our experiments, this was scaled up to 31 workers to test scalability.
restartPolicy: OnFailure: Ensures that if a container fails, Kubernetes will attempt to restart it, contributing to the fault tolerance of the training job.template.spec.containers: Defines the container specifications for each replica type.name: pytorch: The name of the container running the training script.image: gcr.io/dsd-demo-370521/pytorch-dist-ogbl-gloo:1.0: Specifies the Docker image containing our training code and dependencies, pulled from Google Container Registry.imagePullPolicy: Alwaysensures the latest image is used.args: ["--epochs=5"]: Arguments passed to the training script. This allows for flexible configuration of training parameters.volumeMounts: Crucial for data access and logging.mountPath: /data: The path inside the container where the dataset is mounted.mountPath: /tensorboard: The path for writing TensorBoard logs.
template.spec.volumes: Defines the actual volumes that are mounted.persistentVolumeClaim: claimName: nfs: Both/dataand/tensorboardmount claims to an NFS Persistent Volume Claim (PVC), ensuring shared, persistent access to data and logs across all master and worker pods.
By defining these declarative YAML manifests, Kubeflow’s PyTorchJob operator efficiently manages the lifecycle of our distributed training, including creating, scaling, and monitoring the pods, significantly simplifying the deployment of complex ML workloads.
Data Management Strategy: Centralized Access with NFS
Effective data management is paramount for distributed training, ensuring all workers have consistent and performant access to the dataset and can collectively write logs and checkpoints. Our strategy relies on Network File System (NFS) for centralized, shared storage.
The ogbl-citations2 Dataset
As mentioned, we used the ogbl-citations2 dataset. This large graph dataset, representing a citation network, requires efficient handling. Instead of duplicating the dataset on each worker pod, which would be inefficient and resource-intensive, a shared file system allows all pods to access the same data efficiently.
Shared Data Storage with NFS
To provide shared storage, we deployed an NFS server directly within our Kubernetes cluster:
-
NFS Server Deployment: A Kubernetes Deployment and Service were created to run the NFS server. The
nfs-deployment.yamldefines a pod running a Docker image with an NFS server, exposing a volume for sharing.YAML
# Excerpt from nfs/nfs-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nfs-server spec: selector: matchLabels: app: nfs-server template: metadata: labels: app: nfs-server spec: containers: - name: nfs-server image: k8s.gcr.io/e2e-test-images/volume/nfs:1.0 # ... further configuration for exports and volume -
NFS Service: A Kubernetes Service (
nfs-service.yaml) was created to expose the NFS server within the cluster, allowing other pods to discover and connect to it. -
Persistent Volume (PV): A Kubernetes Persistent Volume (
pv-nfs.yaml) was manually provisioned, representing the NFS share. This PV points to the NFS server’s IP address and the exported path.YAML
# Excerpt from nfs/pv-nfs.yaml apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv spec: capacity: storage: 100Gi # Example capacity accessModes: - ReadWriteMany # Crucial for shared access nfs: path: /exports # Exported path on the NFS server server: <NFS_SERVER_IP> # IP of the NFS service -
Persistent Volume Claim (PVC): A Persistent Volume Claim (
pv/pv.yaml) was created, which dynamically binds to thenfs-pv. This PVC (claimName: nfs) is then referenced in thePyTorchJobdefinitions for both the master and worker pods, mounting the shared NFS volume at/datafor the dataset and/tensorboardfor logs.
This setup ensures that all training pods can concurrently read the dataset and write their logs and model checkpoints to the same centralized location.
TensorBoard Deployment and Access
To monitor training progress, TensorBoard was deployed as a separate Kubernetes Deployment and Service.
- TensorBoard Image: A Docker image for TensorBoard was built using
tensorboard/Dockerfile, which includes TensorBoard and sets it to serve logs from a specified directory. - Deployment: The
tensorboard-deployment.yamldefines a deployment for the TensorBoard application, mounting the same NFS PVC (claimName: nfs) to its/tensorboardlog directory. - Access: To expose TensorBoard outside the Kubernetes cluster, an Nginx reverse proxy was used (
nginx/nginx.yaml). This Nginx ingress directs external traffic to the TensorBoard service, allowing developers to access the training visualizations through a web browser.
This comprehensive data management strategy ensures efficient data access, centralized logging, and convenient monitoring for our distributed GNN training jobs.
Deployment and Operational Aspects: From Image to Cluster
Deploying and managing a distributed ML system on Kubernetes involves several critical operational considerations, from building container images to handling runtime challenges.
Google Cloud Build for Image Management
Google Cloud Build played a pivotal role in our CI/CD pipeline for creating and pushing Docker images. Cloud Build automates the process of turning our application code (GNN training script, TensorBoard setup) into ready-to-deploy Docker images.
-
ogbl-cloudbuild.yaml: This configuration defines the steps to build the GNN training image. It usesgcr.io/cloud-builders/dockerto build the Dockerfile (ogbl.Dockerfile) and then push the resulting image to Google Container Registry (GCR).YAML
# Excerpt from ogbl/ogbl-cloudbuild.yaml steps: - name: 'gcr.io/cloud-builders/docker' args: ['build', '-t', 'gcr.io/dsd-demo-370521/pytorch-dist-ogbl-gloo:1.0', '-f', 'ogbl.Dockerfile', '.'] - name: 'gcr.io/cloud-builders/docker' args: ['push', 'gcr.io/dsd-demo-370521/pytorch-dist-ogbl-gloo:1.0'] -
Similarly,
tensorboard/tensorboard-cloudbuild.yamlhandles the build and push for the TensorBoard image. This automation ensures that our training environment is always up-to-date and consistently built.
Challenges Faced and Solutions Implemented
Building a robust distributed ML system on Kubernetes often comes with its share of challenges. Here’s how we addressed them:
- Resource Management:
- Challenge: Ensuring sufficient CPU, memory, and GPU resources for each pod, especially as the number of workers scaled. Preventing resource starvation or over-provisioning.
- Solution: Careful resource requests and limits were defined in the Kubernetes YAMLs for
PyTorchJobreplicas. Monitoring tools (like Google Cloud Monitoring) were essential to observe actual resource utilization and adjust allocations dynamically, ensuring optimal cluster utilization without bottlenecks.
- Networking for Distributed Training:
- Challenge: Establishing reliable and performant communication between PyTorch DDP master and worker pods, especially across different nodes in the Kubernetes cluster. Correctly setting up
MASTER_ADDRandMASTER_PORT. - Solution: Kubeflow’s PyTorchJob operator automates the discovery and configuration of the master and worker services. It sets environment variables like
MASTER_ADDR,MASTER_PORT,RANK, andWORLD_SIZEwithin the pods, allowing PyTorch DDP to correctly initialize communication channels. We utilized theGloobackend for inter-process communication.
- Challenge: Establishing reliable and performant communication between PyTorch DDP master and worker pods, especially across different nodes in the Kubernetes cluster. Correctly setting up
- Shared Data Storage:
- Challenge: Providing a single, consistent, and performant storage solution for the large
ogbl-citations2dataset and for collecting TensorBoard logs and model checkpoints from all distributed worker pods. - Solution: As detailed above, we implemented a robust NFS server within the Kubernetes cluster. This allowed all master and worker pods to mount the same
PersistentVolumeClaim, ensuring ReadWriteMany access for both data loading and log/checkpoint writing. This avoided data duplication and simplified data consistency.
- Challenge: Providing a single, consistent, and performant storage solution for the large
- Fault Tolerance:
- Challenge: Ensuring the training job can recover from transient failures of individual pods or nodes.
- Solution: Kubernetes’ inherent self-healing capabilities were leveraged. The
restartPolicy: OnFailurein ourPyTorchJobdefinitions ensures that if a pod crashes, Kubernetes will automatically restart it. PyTorch DDP itself has mechanisms for dealing with some level of transient failures, though checkpointing is crucial for full job recovery. We relied on regular checkpointing to the shared NFS volume, allowing us to resume training from the last saved state if a larger failure occurred.
These operational considerations and their solutions were vital in building a resilient and efficient distributed GNN training system.
Performance Analysis: Scaling GNN Training
The primary goal of this project was to demonstrate the scalability and efficiency of training GNNs using Kubeflow and PyTorch DDP. Our performance analysis focused on two key metrics: training time and model accuracy, across varying numbers of worker pods. We also monitored resource utilization to understand scalability efficiency.
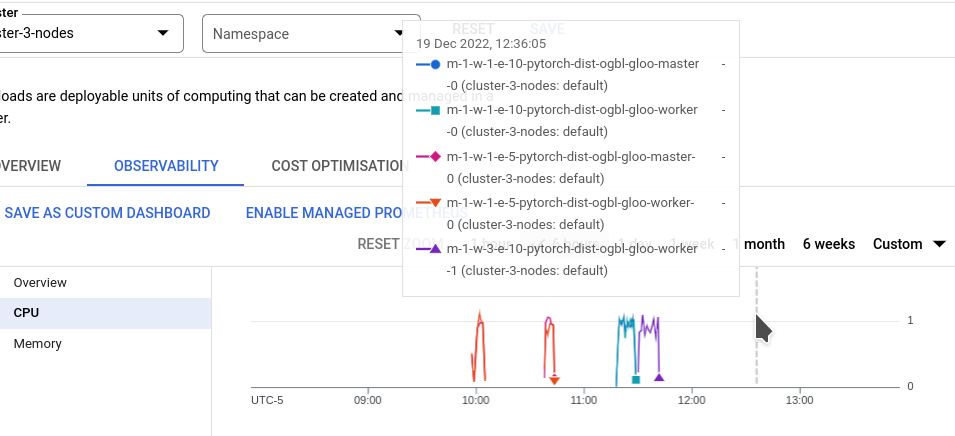
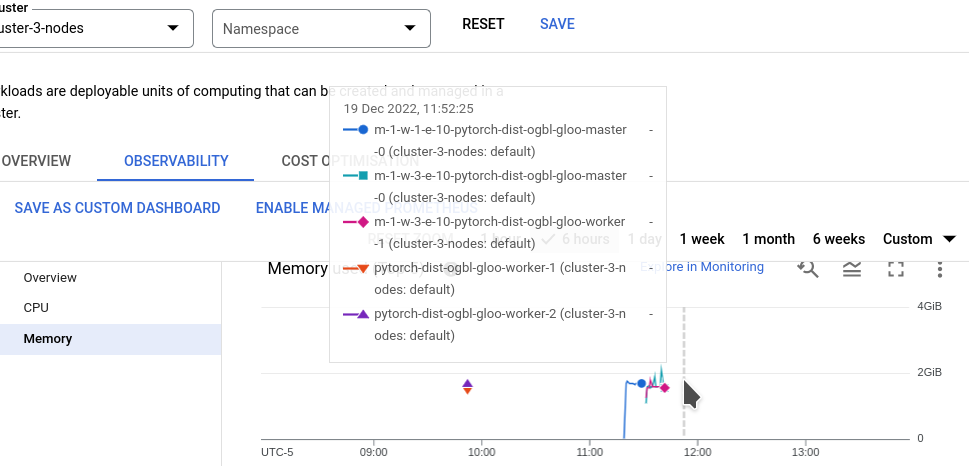
Training Performance
We conducted experiments by varying the number of worker pods (1, 3, 5, 7, 15, 31) while keeping other parameters (e.g., number of epochs) consistent to observe the impact on training duration and final model accuracy.
| Replicas | Epochs | Training Time (min) | Accuracy (%) |
| 1 | 5 | 29.35 | 83.07 |
| 3 | 5 | 20.21 | 84.14 |
| 5 | 5 | 15.65 | 84.77 |
| 7 | 5 | 14.39 | 84.97 |
| 15 | 5 | 11.23 | 85.08 |
| 31 | 5 | 9.88 | 85.15 |
Observations:
- Significant Speedup: As the number of worker replicas increased, the total training time drastically decreased. Moving from 1 to 31 workers for 5 epochs resulted in an approximate 3x speedup (from 29.35 minutes to 9.88 minutes).
- Diminishing Returns: While the speedup is substantial, the rate of speedup tends to decrease as more workers are added. This is a common characteristic of distributed systems due to overheads like communication, synchronization, and potential load imbalance. For example, going from 15 to 31 workers yielded a smaller absolute reduction in time compared to going from 1 to 3 workers.
- Consistent Accuracy: Crucially, increasing the number of workers did not negatively impact the model’s accuracy. In fact, there was a slight trend towards higher accuracy with more workers (e.g., 83.07% for 1 worker vs. 85.15% for 31 workers). This is likely due to the
DistributedSamplerensuring that each worker processes unique data, potentially leading to a more robust overall training process as the effective batch size across all workers increases.
Scalability and Resource Sharing
Monitoring CPU and memory usage of the pods provided insights into resource utilization and the efficiency of scaling.
- CPU Usage: On average, each pod utilized approximately 1.16 CPU cores. This indicates that the workload was well-distributed and that each worker was actively engaged in computation. The relatively low average core usage per pod suggests that the system was not CPU-bound and could potentially handle even larger workloads or more intensive computations per worker.
- Memory Usage: The memory consumption was also monitored to ensure no worker ran out of memory, which is critical for GNNs that can be memory-intensive due to graph structures. The successful completion of training across all worker configurations indicates effective memory management.
These results unequivocally demonstrate the effectiveness of using Kubeflow and PyTorch DDP for scaling GNN training. The system exhibited strong horizontal scalability, significantly reducing training times without compromising model performance, while efficiently utilizing cluster resources.
Conclusion: Scalable GNN Training with Kubeflow
This project successfully demonstrated a robust and scalable solution for training Graph Neural Network models on large datasets leveraging Kubeflow and PyTorch Distributed Data Parallel (DDP) within a Kubernetes environment. In summary we can reduce training time significantly by distributed training, monitor the training with shared Tensorboard instance and NFS storage, and can have falut-tolerant training with checkpointing and kubernetes’s self-healing restart policies, levarage cloud builds for effective image builds (caching etc) directly in cloud.